
如今治學,影印少了,更多的是在網上操作。
PDF幾乎成了通用的文件交換模式,所以要用各種方法提取當中的資料。例如公益版圖書有些是沒有經過認字加工的,只是圖像,不能擷取。
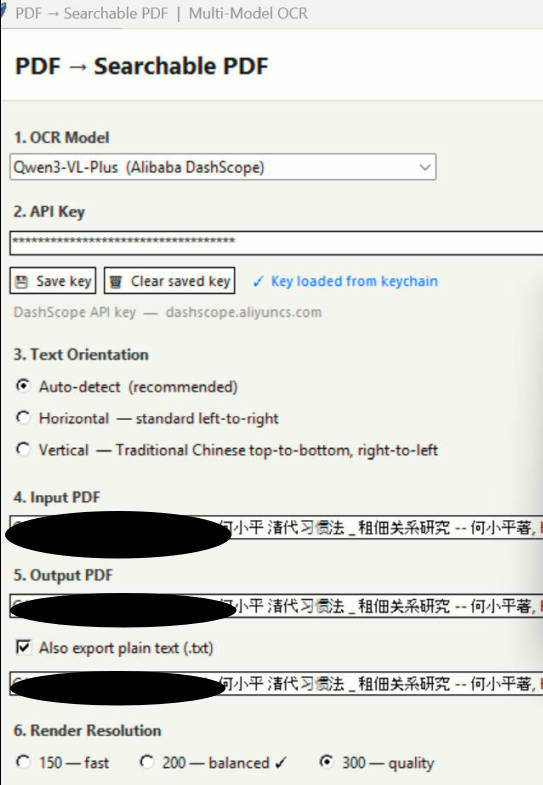
要充份利用,第一是要OCR認字,認字也有兩種,一是變成 searchable 的 PDF, 二是提取其中文字。本來 searchable PDF 已很好用,但要有專門的製作軟件。ABBYY是不錯的,但太太貴了,我訂過兩年,如今仍是用舊的公益版。Monica OCR 也不錯,效果比 ABBYY 更好,但要切割成每份最多50M上傳。
昨天想用 AI 自製一個,既可製作 searchable PDF 也能輸出文字檔的,在本機運作,用python. PDF search 是可以,但不能在原稿上的正確位置標示,作用不大,所以放棄了,還是用 Monica。
至於文字檔,則效果不錯,而且可以輸出成 Markdown 格式,方便二次利用。今早花了兩個鐘,製作了以 python 為後台的網上工具,這是我第一次做這東西,因為要在server做點改動,怕一旦出錯一切化為烏有,有點手震震。經過多次除錯後,終於成功。
介面。上傳PDF,通過AI轉為文字檔或markdownd格式,可選強制輸出繁體。
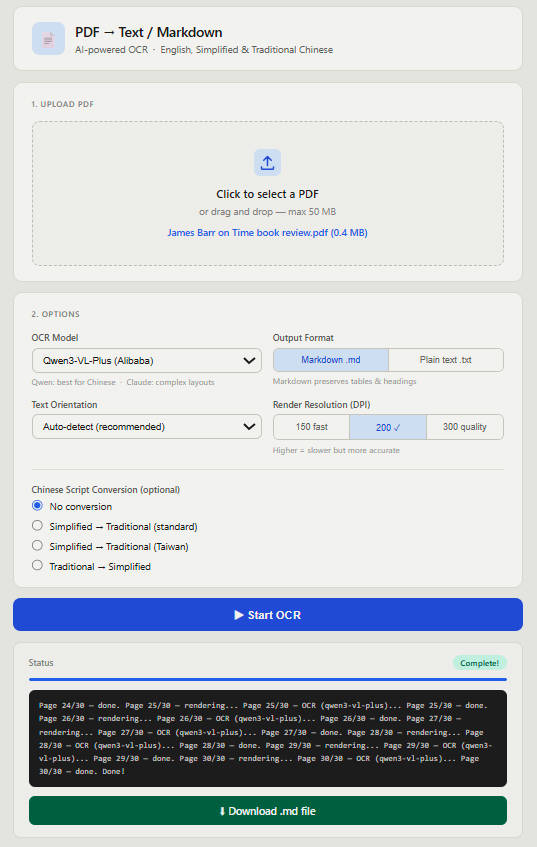
MD格式是文字加標記,用閱讀器就可變成漂亮的PDF。

